Key Contributions #
Generalize across objects
The same policy lifts and manipulates objects with diverse geometry (e.g., 23 cm box to 60 cm cylinder) by operating on a distance-field representation.
How we achieve this
We represent interaction in a distance-field space, which acts like a quotiented task space over object geometry. This gives the policy dense local geometric cues that transfer across object shape and scale without redesigning task formulations.
Multiple skills in one policy
A single policy composes pick up, push, sit/stand, and carry over long horizons without task-specific modules.
How we achieve this
We build a unified interaction representation shared by all skills. With one common observation/reward interface across interactions, a single policy can learn skill composition from consistent inputs rather than isolated per-task pipelines.
No hand-crafted reward
Training uses adversarial interaction priors in the geometric domain instead of motion-tracking or hand-designed shaping rewards.
How we achieve this
We use discriminative objectives to enforce natural and physically reasonable interaction trajectories. This removes the need for brittle task-specific reward shaping and improves behavior quality across diverse interaction modes.
Root command & action label only
At inference, control is specified solely by target root trajectory and action labels; no motion exemplars or retargeting.
Why this matters
We simplify control inputs to root commands plus action labels, making human-in-the-loop control straightforward and enabling clean integration with upstream planners or VLM-driven instruction modules.
How We Do It
We use a distance-field-centric policy representation. The top row visualizes DF-driven interaction for three different skills (pick, push, sit), and the second row shows scale generalization.
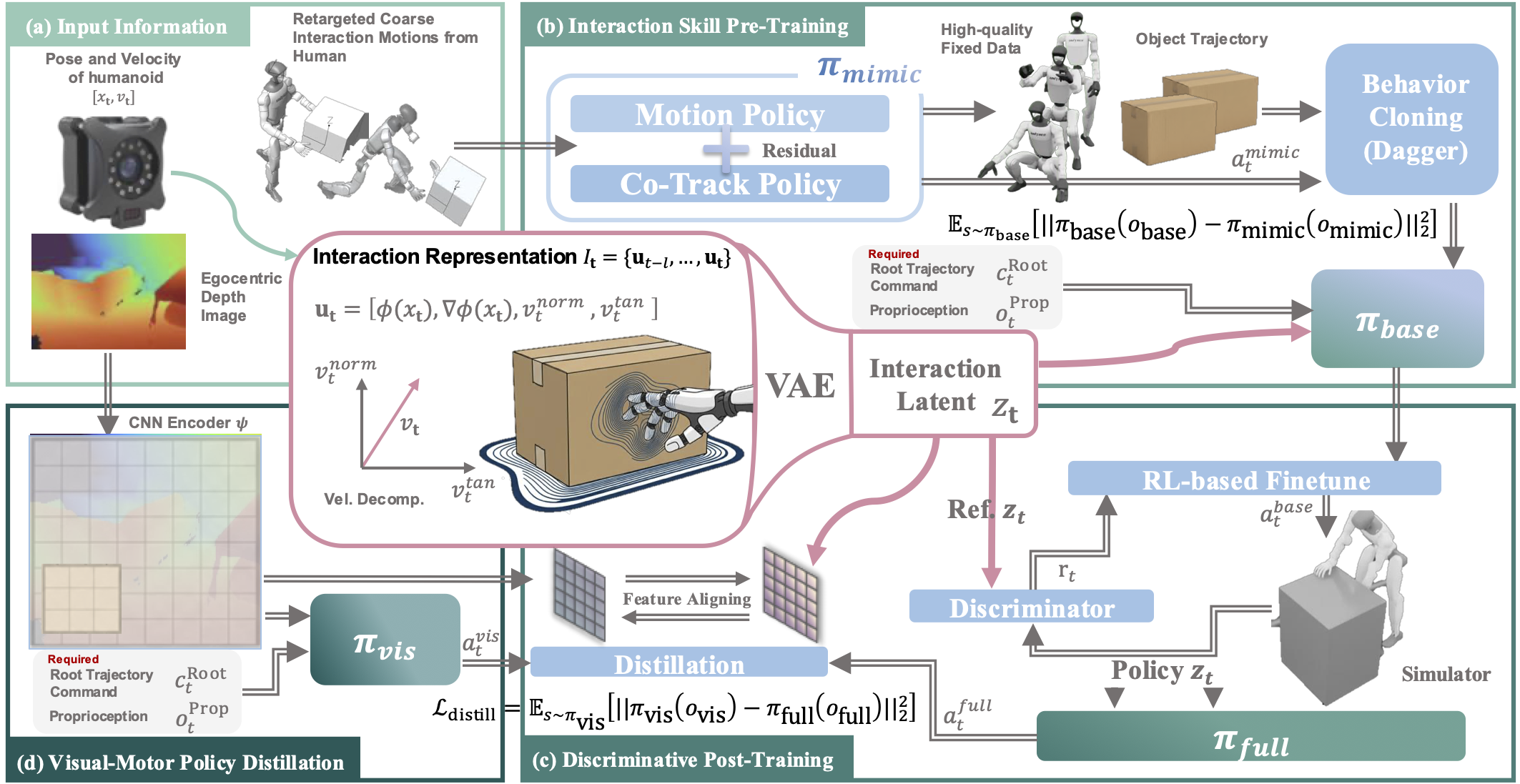
Method Overview
Unified distance-field representation and policy learning pipeline.
Live MuJoCo Session
Use this embedded session to inspect online rollout behavior directly in-browser. Add your own objects to the session and interact with them.
Feel free to test how purely data-driven interaction policy complete tasks (or fail).
The live simulator is paused by default to avoid heavy startup on page load.
Hosted locally for reproducible demos and GitHub Pages compatibility.
Open it in a new tab if you need more space:
Humanoid Policy Viewer.
Note: The objects' DF is discretized and cached, so the policy's performance is slightly degraded. To report issues, please contact yutang.lin@stu.pku.edu.cn.
Please use Google Chrome for best performance.
1. Interact with Various Objects #
One policy generalizes across object shapes and sizes—box, foam cylinder, and ball.
*The foam cylinder and soccer ball are not in training data.
2. Autonomously Recover from Disturbance/Failure #
After external disturbance or failed pickup attempts, the policy re-initiates interaction and recovers autonomously using continuous geometric feedback.
3. Execute Consequent Long-Horizon Tasks #
A single policy composes multiple skills in sequence over extended horizons, showing smooth transitions between interaction modes.
4. Mocap and Depth Input as Perception #
Our method runs with either motion-capture object state or egocentric depth only—enabling deployment with or without external tracking.
Same task: left = mocap object state, right = depth-only policy.
Additional Vision-Only Demos
Our method can push objects with different geometries and scales. Thanks Yixuan for his dedication 😁.
Long-horizon completion: push + pick (vision). Right: egocentric depth perception.
Quantitative Results at a Glance #
Visual summaries: simulation scale generalization, long-horizon completion, and real-world deployment.
Single-Task Scale Generalization (Ours)
One merged figure for PickUp success across object scales (from TABLE II).
Long-Horizon: Ours (Mocap) Only
Completion rate of our main method as the number of sequential tasks increases.
Abstract #
Humanoid robots that autonomously interact with physical environments over extended horizons represent a central goal of embodied intelligence. Existing approaches rely on reference motions or task-specific rewards, tightly coupling policies to particular object geometries and precluding multi-skill generalization within a single framework. A unified interaction representation enabling reference-free inference, geometric generalization, and long-horizon skill composition within one policy remains an open challenge. Here we show that Distance Field (DF) provides such a representation: LessMimic conditions a single whole-body policy on DF-derived geometric cues—surface distances, gradients, and velocity decompositions—removing the need for motion references, with interaction latents encoded via a Variational Autoencoder (VAE) and post-trained using Adversarial Interaction Prior (AIP)-derived Reinforcement Learning (RL). Through DAgger-style distillation that aligns DF latents with egocentric depth features, LessMimic further transfers seamlessly to vision-only deployment without motion capture infrastructure. A single LessMimic policy achieves 80–100% success across object scales from 0.4× to 1.6× on PickUp and SitStand where baselines degrade sharply, attains 62.1% success on 5-task trajectories, and remains viable up to 40 sequentially composed tasks. By grounding interaction in local geometry rather than demonstrations, LessMimic offers a scalable path toward humanoid robots that generalize, compose skills, and recover from failures in unstructured environments.
Paper (PDF)
If the PDF does not display, download it directly.
BibTeX
@article{lin2026lessmimic,
title={LessMimic: Long-Horizon Humanoid Interaction with Unified Distance Field Representations},
author={Yutang Lin and Jieming Cui and Yixuan Li and Baoxiong Jia and Yixin Zhu and Siyuan Huang},
journal={arXiv preprint arXiv:2602.21723},
year={2026}
}